|
I am a research scientist at Keen Technologies working on continual and reinforcement learning. My long-term research goal is to understand how our minds work. Specifically, to help find the computational principles that give rise to the mind. In pursuit of this goal, I'm working on various aspects of continual learning, deep learning, and reinforcement learning. Previously, I completed a Ph.D. at the University of Alberta, advised by Dr. Richard Sutton and Dr. Rupam Mahmood. I completed my B.Tech. at IIT Kanpur in Computer Science and Engineering. During my Ph.D., I contributed to exposing a fundamental problem with deep learning systems, where these systems can lose the ability to learn new things. This work was published in Nature and featured in some popular media outlets, such as New Scientist. If you prefer podcasts, I have also discussed my work on the Nature Podcast and AMII's Approximately Correct Podcast. Continual learning is increasingly being applied in the industry. I think many applications require continual adaptation, and deep continual learning has big potential in the next 5 years. See a list of possible applications here. Email / CV / Google Scholar / Github |

|
|
|

|
Shibhansh Dohare PhD Thesis, University of Alberta, 2025 My thesis brings together my work on loss of plasticity, continual backpropagation, and policy collapse. It provides a deeper understanding and evaluation of continual backpropagation than prior papers. There is also a new chapter on formalisms for loss of plasticity. Additionally, it also contains extensive discussion of related work in other fields as well as of prior work. |
|
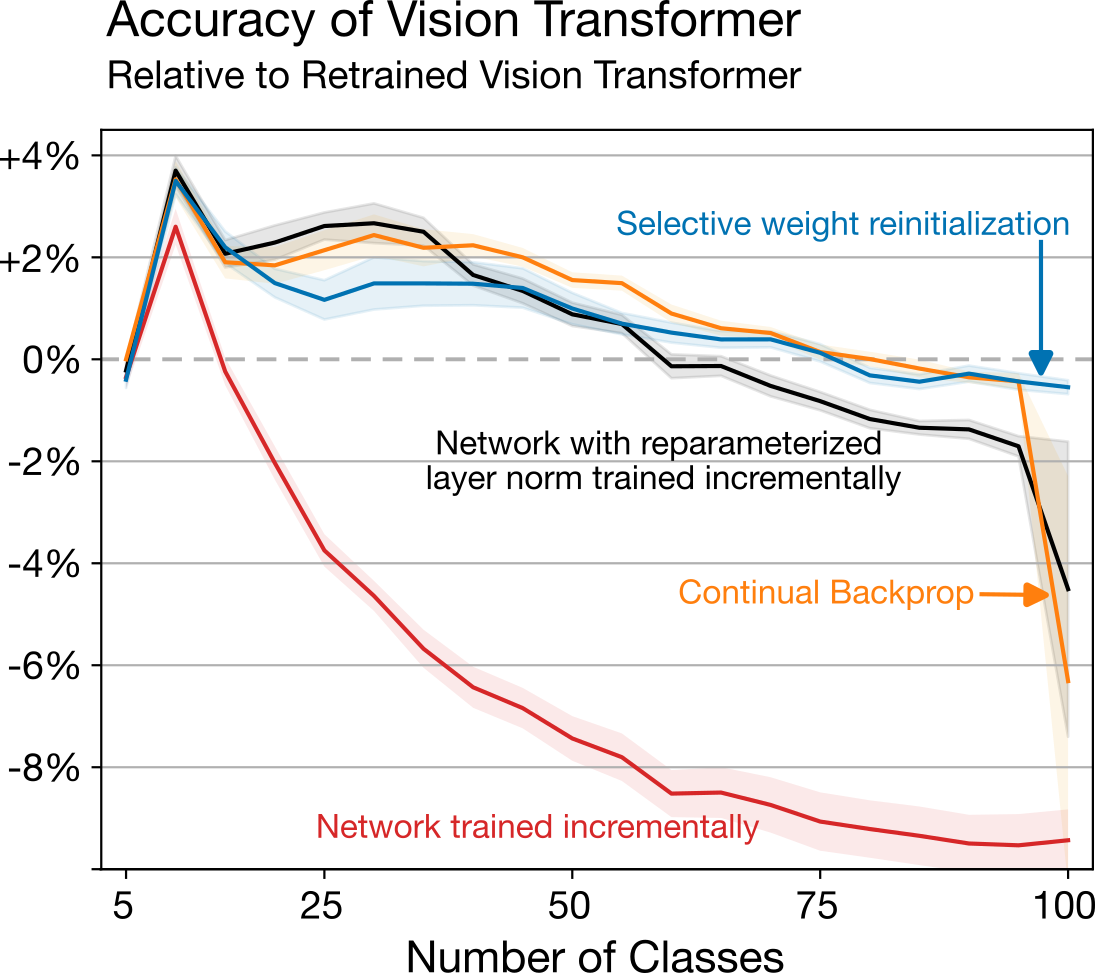
J. Fernando Hernandez-Garcia, Shibhansh Dohare, Jun Luo, Richard S. Sutton CoLLAs, Oral Presentation, 2025 Paper | Code This paper builds on our Nature paper. We propose a new algorithm, which we name selective weight reinitialization, for reinitializing the least useful weights in a network.
We find that selective weight reinitialization is more effective at maintaining plasticity than reinitializing units (continual backpropagation) when the network includes layer normalization or attention layers. |
|
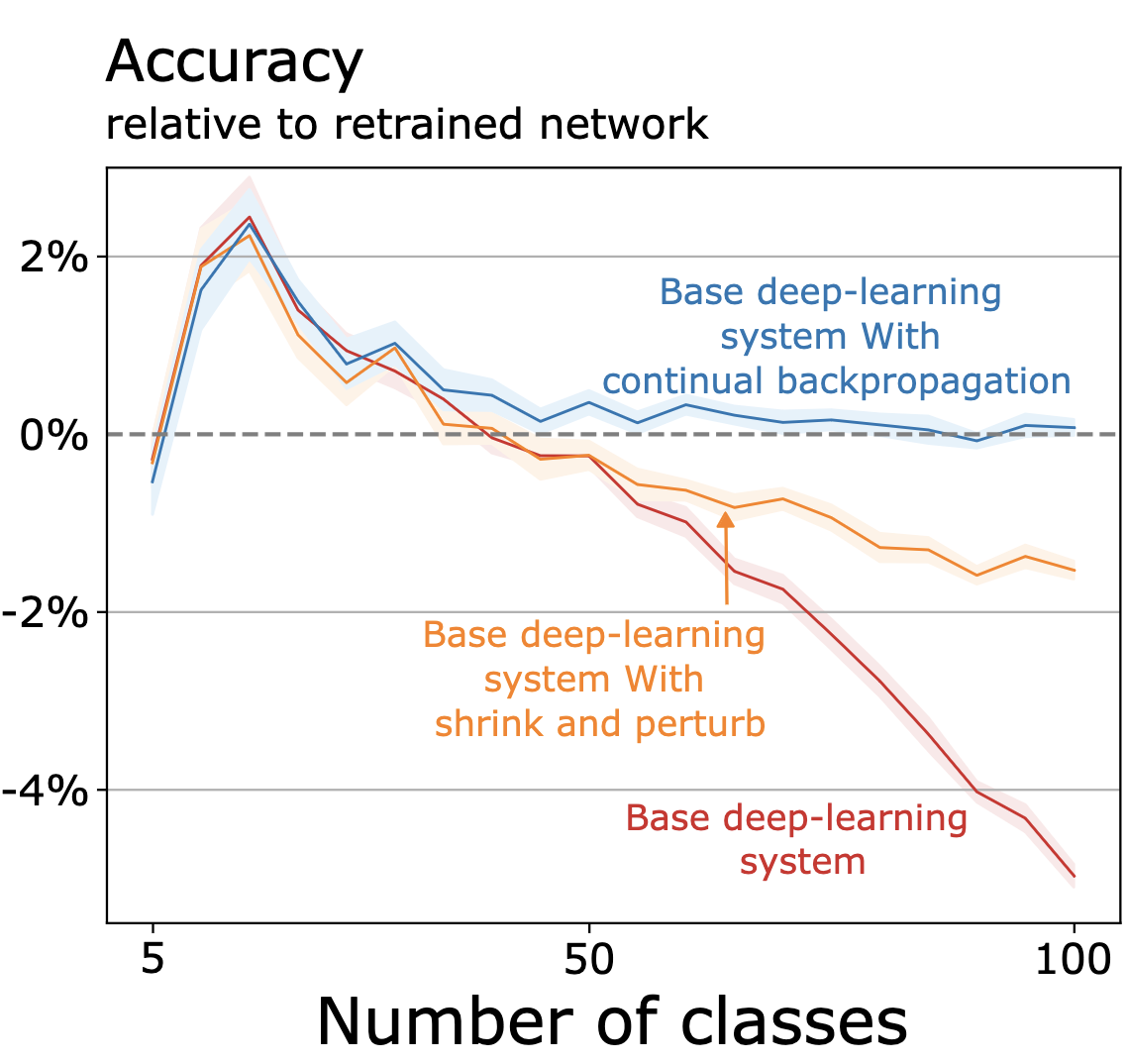
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A. Rupam Mahmood, Richard S. Sutton Nature 2024 Paper | Code | Nature Podcast | News We provide direct demonstrations of plasticity loss in deep continual learning. We propose a new algorithm, continual backpropagation, that fully maintains plasticity. Continual backpropagation reinitializes a small fraction of less-used units alongside gradient descent at each update. |
|
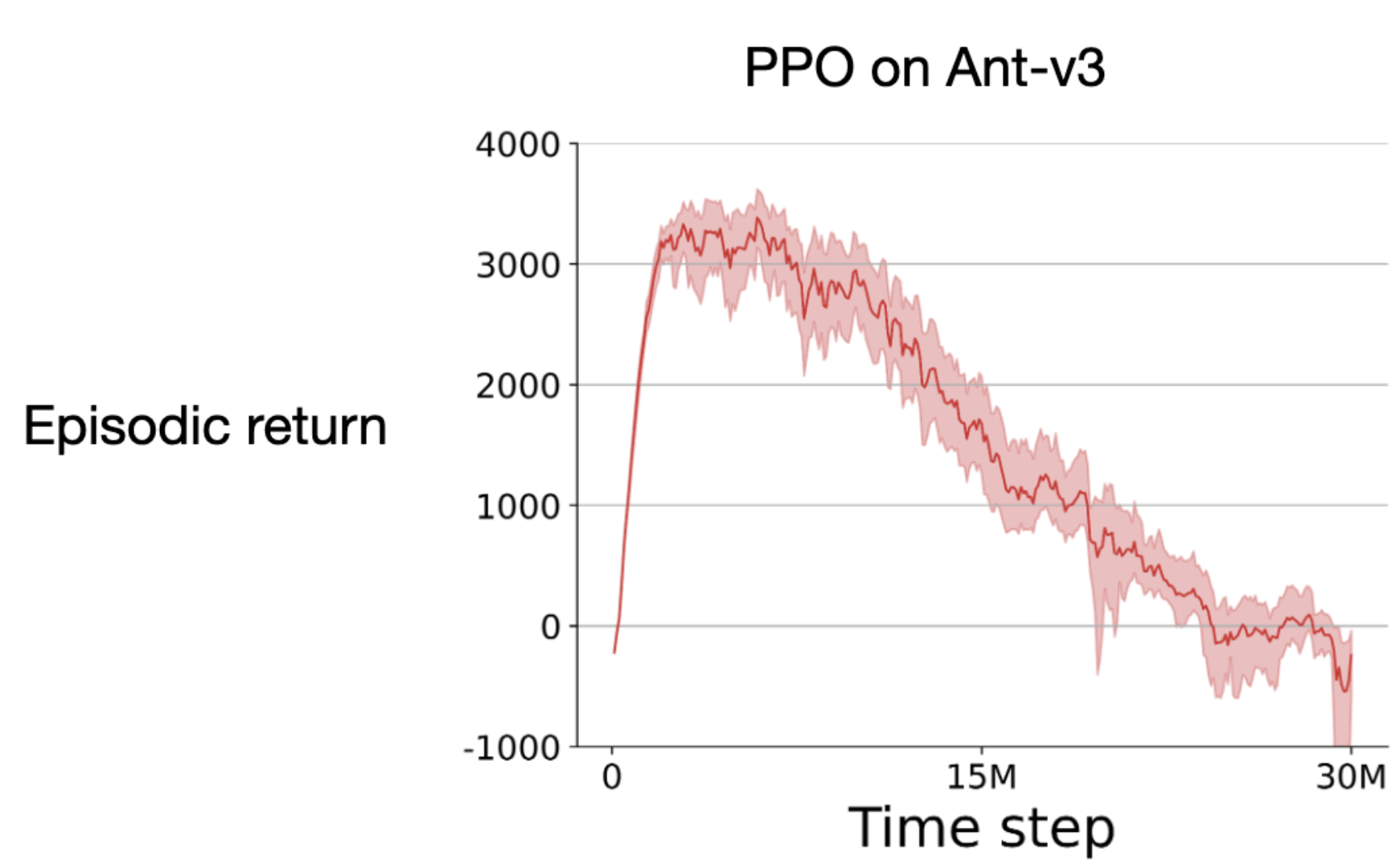
Shibhansh Dohare, Qingfeng Lan, A. Rupam Mahmood EWRL 2023 Paper We show that popular deep RL algorithms, like PPO, do not scale with experience. Their performance gets worse over time. We look deeper into this problem and provide simple solutions to reduce performance degradation. |
|
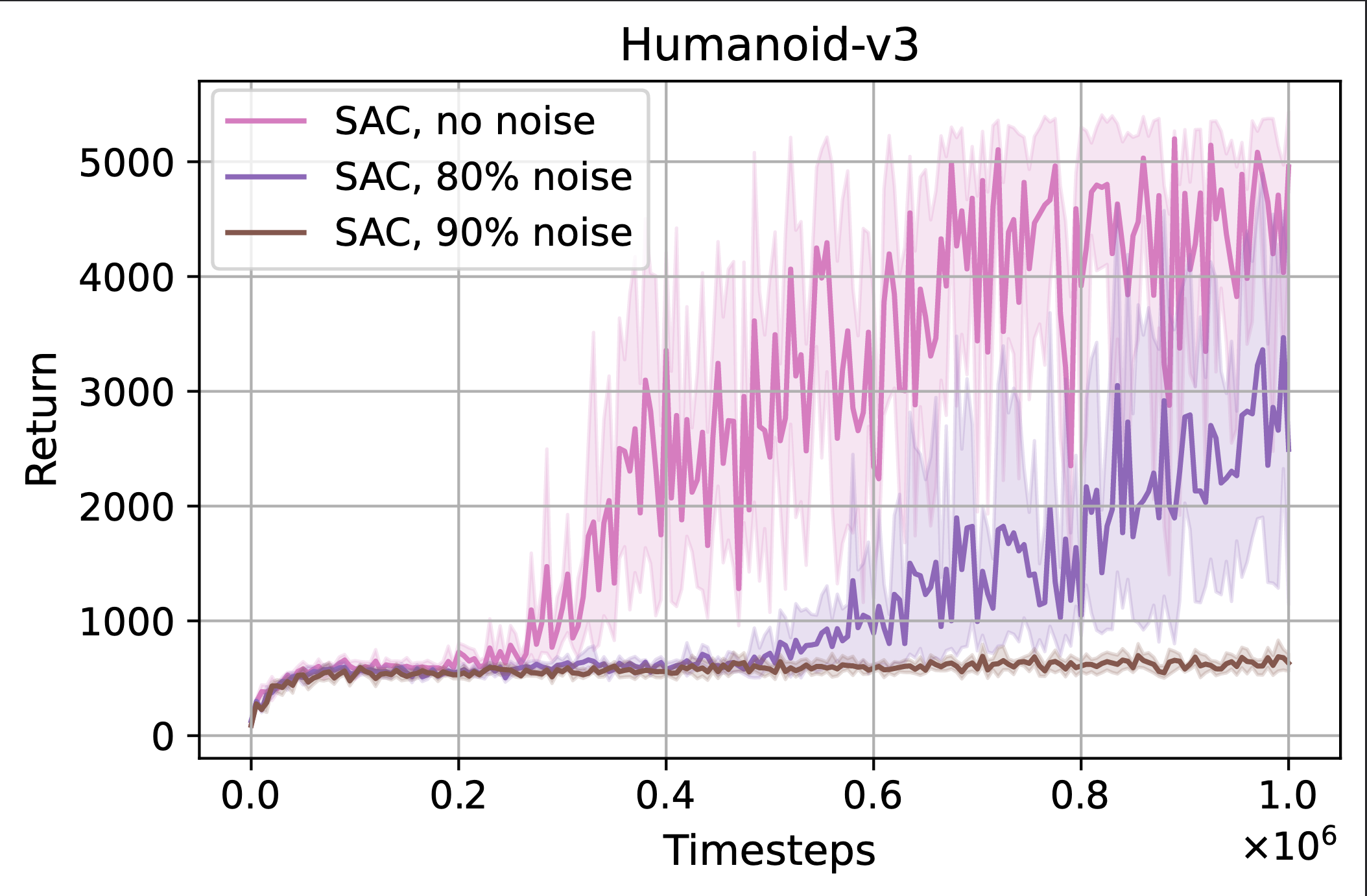
Bram Grooten, Ghada Sokar, Shibhansh Dohare, Elena Mocanu, Matthew E. Taylor, Mykola Pechenizkiy, Decebal Constantin Mocanu AAMAS 2023 Paper We show that standard Deep RL algorithms fail when the input contains noisy features. Dynamic sparse training successfully filters through the noisy features and performs well. |
|
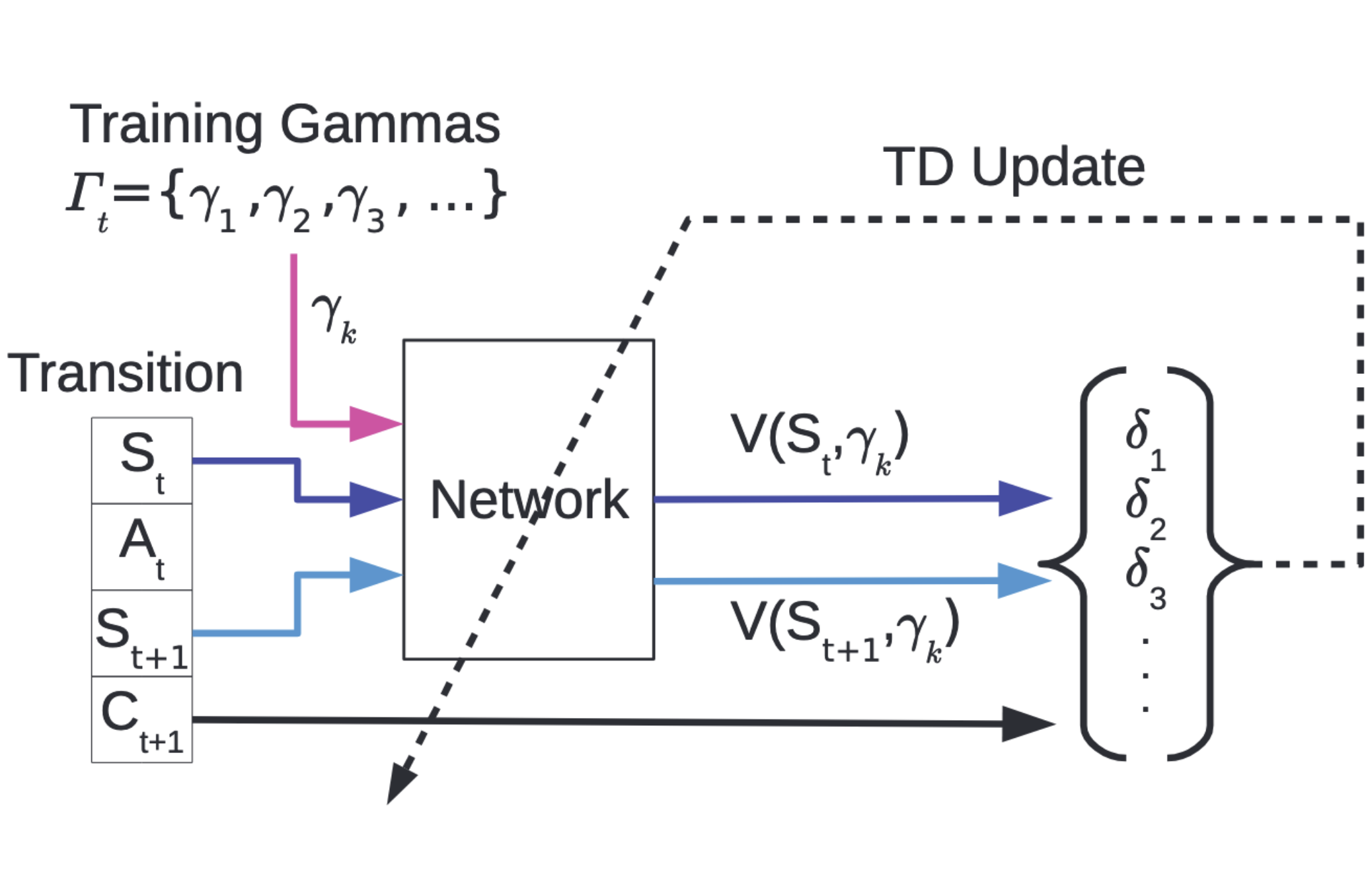
Craig Sherstan, Shibhansh Dohare, James MacGlashan, Johannes Günther, Patrick M. Pilarski, AAAI, Oral Presentation, 2020 Paper We present Gamma-nets, a method for generalizing value function estimation over timescale. |
|
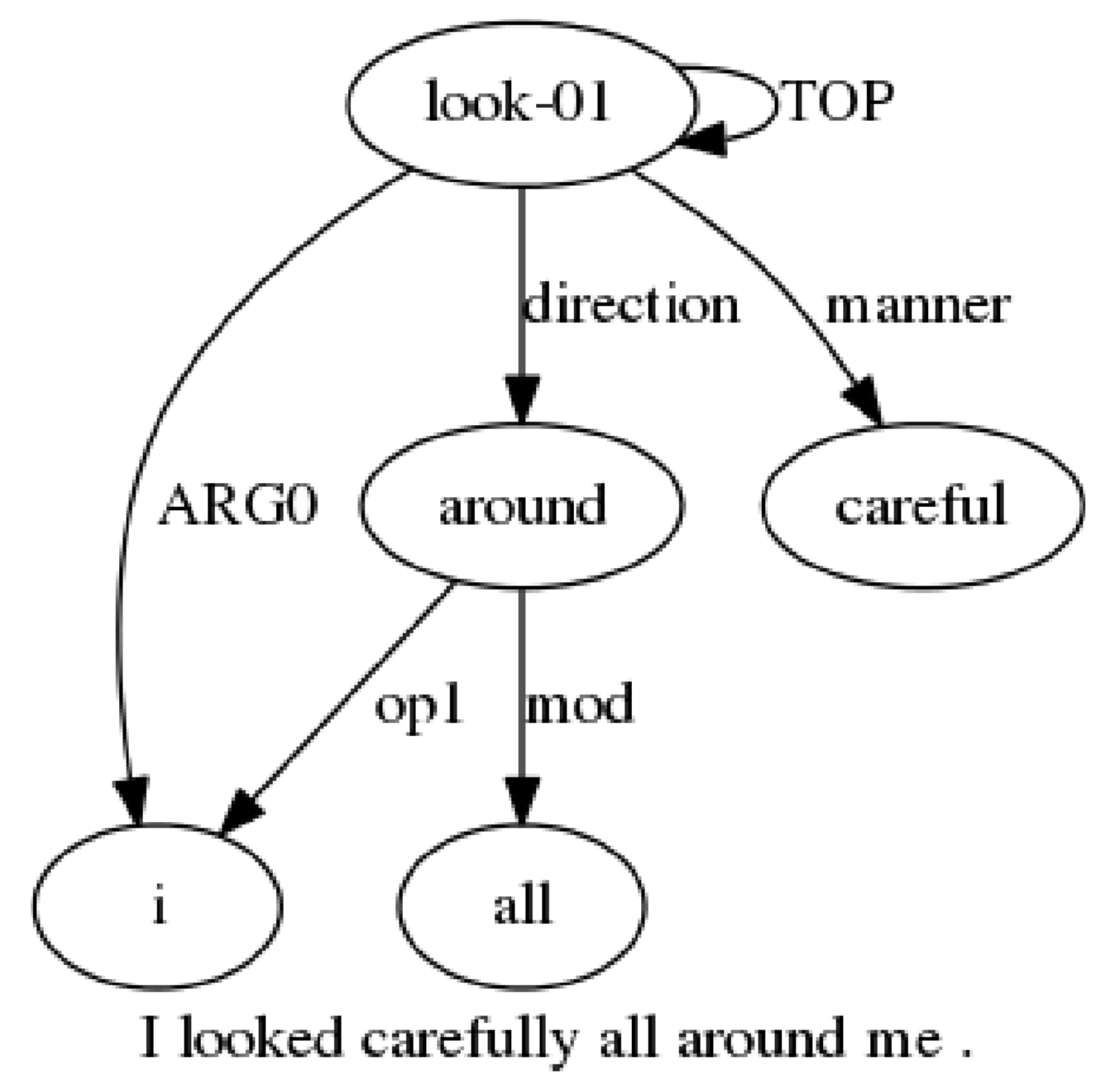
Shibhansh Dohare, Vivek Gupta, Harish Karnick, ACL, Student Research Workshop, 2018 Paper A novel algorithm for abstractive text summarization based on Abstract Meaning Representation. |
|
Website design credit goes to Jon Barron. |